前端大神器——puppeteer无头浏览器
前端大神器——puppeteer无头浏览器
# 介绍
利用Puppeteer可以获取页面DOM节点、网络请求和响应、程序化操作页面行为、进行页面的性能监控和优化、获取页面截图和PDF等,利用该神器就可以操作Chrome浏览器玩出各种花样,非常的有趣~
# 是什么
Puppeteer 是一个 Node 库,它提供了高级的 API 并通过 DevTools 协议来控制 Chrome(或Chromium)。通俗来说就是一个 headless chrome 浏览器 (也可以配置成有 UI 的,默认是没有的)
# 结构
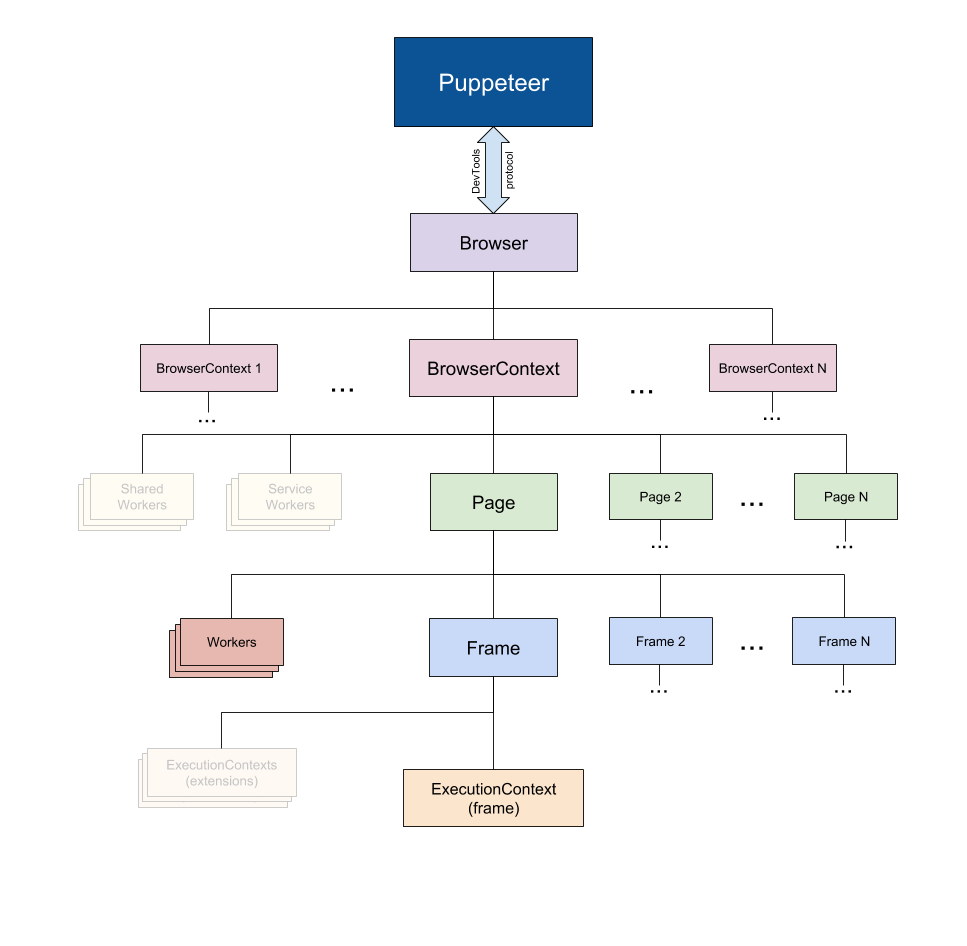
- Browser:这是一个浏览器实例,可以拥有浏览器上下文,可通过
puppeteer.launch或puppeteer.connect创建一个Browser对象。 - BrowserContext:该实例定义了一个浏览器上下文,可拥有多个页面,创建浏览器实例时默认会创建一个浏览器上下文(不能关闭),此外可以利用
browser.createIncognitoBrowserContext()创建一个匿名的浏览器上下文(不会与其它浏览器上下文共享cookie/cache). - Page:至少包含一个主框架,除了主框架外还有可能存在其它框架,例如
iframe。 - Frame:页面中的框架,在每个时间点,页面通过
page.mainFrame()和frame.childFrames()方法暴露当前框架的细节。对于该框架中至少有一个执行上下文 - ExecutionCOntext:表示一个
JavaScript的执行上下文。 - Worker:具有单个执行上下文,便于与
WebWorkers交互。
# 可以做什么
- 生成网页截图或者 PDF
- 抓取 SPA(单页应用)并生成预渲染内容(即“SSR”(服务器端渲染))
- 做表单的自动提交、UI的自动化测试、模拟键盘输入等
- 用浏览器自带的一些调试工具和性能分析工具帮助我们分析问题
- 在最新的无头浏览器环境里做测试、使用最新浏览器特性
- 测试浏览器扩展
# 使用
# 安装
npm i puppeteer or yarn add puppeteer
当你安装 Puppeteer 时,它会下载最新版本的Chromium(~170MB Mac,~282MB Linux,~280MB Win),以保证可以使用 API。 如果想要跳过下载,请阅读环境变量。
npm i puppeteer-core or yarn add puppeteer-core
自 1.7.0 版本开始,官方每次回同步发布一个puppeteer-core,这个包默认不会下载 Chromium。 puppeteer-core 是一个的轻量级的 Puppeteer 版本,用于启动现有浏览器安装或连接到远程安装。
puppeteer-core、 puppeteer vs puppeteer-core
# 简单使用
Puppeteer 至少需要 Node v6.4.0,下面的示例使用 async / await,它们仅在 Node v7.6.0 或更高版本中被支持。
Puppeteer 使用起来和其他测试框架类似。你需要创建一个 Browser 实例,打开页面,然后使用 Puppeteer 的 API。
# 截图保存
例如,我们打开页面并跳转至 https://ssscode.com/,然后保存截图至 ssscode.png
const puppeteer = require('puppeteer');
(async () => {
// 启动chrome浏览器
const browser = await puppeteer.launch();
// 创建一个新页面
const page = await browser.newPage();
// 页面指向指定网址
await page.goto('https://ssscode.com');
// 截图
await page.screenshot({path: 'ssscode.png'});
// 关闭
await browser.close();
})();
2
3
4
5
6
7
8
9
10
11
12
13
14
# 生成PDF
注意:page.pdf() 必须在无头模式下才可以调用
async function main() {
// 启动浏览器,基本步骤同上
...
// 根据网页内容生成pdf文件
await page.pdf({
path: './ssscode.pdf'
});
browser.close();
}
main();
2
3
4
5
6
7
8
9
10
11
12
13
# 实战
爬取阮一峰老师的 ES6 入门教程,并生成PDF文件到本地~